一、适用行业

二、行业痛点



设备制造业的传统质检过程繁琐,工作人员需手动记录设备屏幕上温度等关键数据,耗时且效率不高,且手动记录数据时,容易受到人为因素的影响,导致数据记录不准确,从而影响质量控制。
三、解决方案
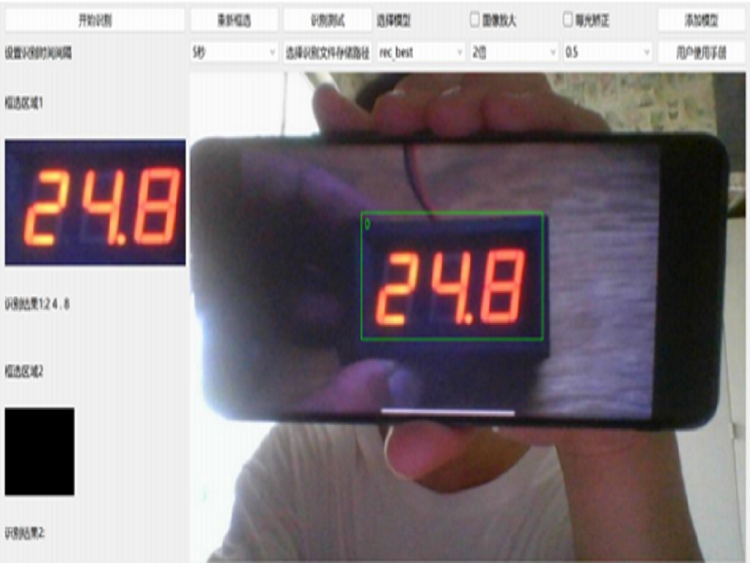
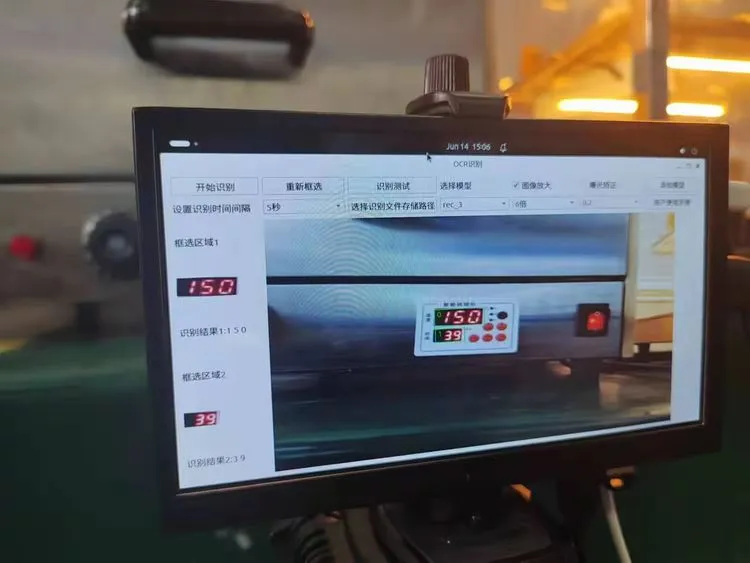
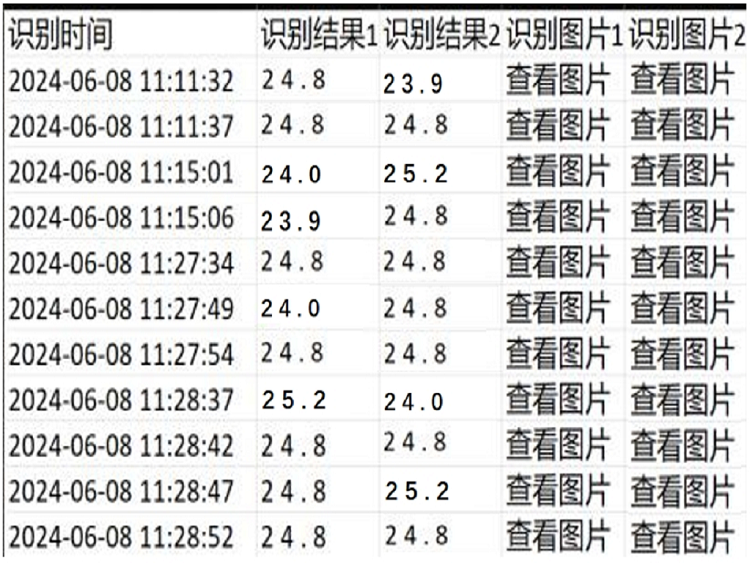
我们春晖信息公司提供了一套数字识别视觉检测系统,该系统能够精准捕捉并解析生产设备屏幕上所显示的数字信息,如温湿度、时间等关键数据,同时所有识别结果和图片自动存储在Excel表格中,支持随时查看各节点历史数据记录。
四、可满足客户定制化需求

五、功能亮点
六、实现效果
该系统通过视觉检测的方式,能够实时记录各种关键数据,显著提升质检效率,取代人工记录的繁琐过程,避免因人为因素导致的误差,提高数据的准确性与可靠性。

七、知识产权
